Update!
I believe this has been very solidly refuted by Anthropic’s paper, Privileged Bases in the Transformer Residual Stream. The TL;DR is that the privileged basis is almost certainly the result of normalization in the Adam optimizer. As I say over here, it is known that the best way to get a right answer is to write the wrong answer on the stalls in the CS department and wait for someone to correct you. I’m thrilled that Nelson, Robert, and Chris did all the hard work and better tests and that I now get to call them coworkers.
Original Post
I was talking to Neel Nanda the other day and he claimed that there seems to exist some sort of regularization such that transformers favor the standard basis for features. I wondered whether this might be due to floating point roundoff when features are of very different magnitudes. As he does, he ran off and had an experiment rigged up like thirty minutes later showing that it’s plausible. I reproduced his experiment to try to clear up some confusion I still had around this, but it does in fact seem like a plausible story.
Here’s the setup: Generate a $d$-long feature vector, $\vec{v}$, of all ones, except with the first value as $k$ orders of magnitude larger than the rest, e.g. $[1e8, 1, 1, 1]$. Generate a random $d \times d$ rotation matrix, $\mathbf{R}$. Rotate $\vec{v}$ by $\mathbf{R}$ and then back by $\mathbf{R}^\intercal$. We should recover $\vec{v}$, but in practice we’ll see some changes to the small values due to floating point roundoff when the small features get mushed together into being co-represented by the same floating point value as the large features.
Here’s a plot of what that looks like when using various floating point types:
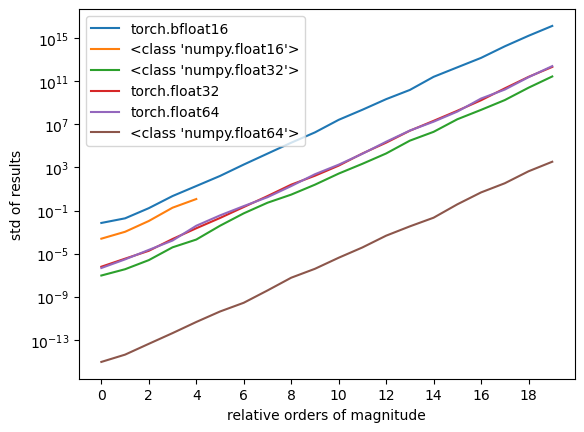
If this is right, we hit 1% error on a bfloat16 when the features span only a single order of magnitude! (1% is chosen arbitrarily as “an amount that sounds bad to lose”) Here’s a table of the orders of magnitude before hitting 1% error for various types:
| fp type | OOM |
|---|---|
| t.bfloat16 | 1 |
| np.float16 | 3 |
| t.float32 | 5 |
| t.float64 | 5 |
| np.float32 | 6 |
| np.float64 | 14 |
As a sanity check, bfloat16 has 8 bits of significand precision (can represent ±256) and starts seeing 1% loss when trying to mix features on a scale of 10 and 1. This seems a bit lower than I’d naively expect – surely we’re not in trouble until we’re mixing 100s and 1s – but I now think this makes sense and actually illustrates how the problem is even worse than I originally thought. If the issue was simply that a 10 and 1 might be rotated into a single value, we’d be fine. But if we rotate, say, 7 of the 10 into one float, and .01 of a 1 into that same float, then we’re stuck trying to represent 7.01 and bfloat16 is already in trouble.
float16 has 11 bits of significant precision (±2048) and starts seeing issues when mixing 1000s and 1s. np.float32 has 24 bits (±16777216) and creaks at 1000000. And np.float64 gets 53 bits maxing out around 10e16, and starts hurting when mixing 10e14 with 1s. A not crazy rule seems to be that we start seeing 1% issues when we start mixing 1s with a numbers around 1% of a floating point type’s max value. In fact, we seem to get X% issues when mixing 1s with X% of the type’s max value.
A great question is “what’s going on with pytorch’s t.float32 and t.float64 types?” I honestly don’t know. It’s likely a bug in my test harness, especially the t.float64 case involving accidentally downcasting to 32 bits somewhere, but I can’t pin it down. I included them for honesty’s sake. I don’t think this invalidates the numpy results and maybe one of you can spot what’s going on. Full code replicated at the end for poking at.
This got me wondering about how much this might be occuring in practice and I tried to find papers discussing typical features magnitudes. LLM.int8() talks about this a bit and seems to come up with large outlier features of around magnitude 50. I don’t see discussion of the size of small features, so it’s tough to gauge the orders of magnitude involved, but unless there are features down around 0.0001 (unlikely?) then maybe this isn’t a big deal in practice for float32 precision and up. Or maybe this is a nice story about why we don’t see larger features (also unlikely?)
As promised earlier, here’s the code to replicate, though there’s a slightly updated version living in this repo.
import numpy as np
import torch as t
from typing import Tuple
import matplotlib.pyplot as plt
def test_rotation(dim: int=10, small_val: float = 0.01, num_large_vals: int = 2, orders_of_magnitude: int = 2, dtype = t.float32) -> Tuple[np.ndarray, np.ndarray]:
"""
dim: Dimension of space
small_val: Value for the "base" values
num_large_values: How many big values at the start
orders_of_magnitude: How many orders of magnitude should the large values be than the small ones
dtype: dtype to do this all in
"""
assert num_large_vals < dim
# Handle both torch and numpy dtypes in this function
backend = t if isinstance(dtype, t.dtype) else np
backend_randn = t.randn if backend == t else np.random.randn
# If we can't even store the large number to begin
# with, this test isn't interesting
if 10 ** orders_of_magnitude > backend.finfo(dtype).max:
return (None, None)
vec = backend.ones((dim,), dtype=dtype) * small_val
vec[0:num_large_vals] *= 10.0 ** orders_of_magnitude
# Generate a random rotation matrix
rot = backend.linalg.svd(backend_randn(dim, dim), full_matrices=True)[0]
rot = rot.to(dtype) if backend == t else rot.astype(dtype)
# Rotate vec out and back again
vec_result = vec @ rot @ rot.T
return vec, vec_result
types = [t.bfloat16, np.float16, np.float32, t.float32, t.float64, np.float64]
printed = []
res = {typ: [] for typ in types}
for dtype in types:
for i in range(20):
num_large_vals = 3
out, back = test_rotation(num_large_vals=num_large_vals, orders_of_magnitude=i, dtype=dtype, small_val=1)
if back is not None:
# What's the std of the small values? If there's no loss in precision it would be 0.
back_std = back[num_large_vals:].std()
# matplotlib is unhappy plotting bfloat16
if dtype == t.bfloat16:
back_std = back_std.to(t.float32)
res[dtype].append(back_std)
if back_std > 0.01 and dtype not in printed:
print(dtype, i, back_std)
printed.append(dtype)
for k, l in res.items():
plt.plot(l, label=k)
plt.yscale('log')
plt.xlabel("relative orders of magnitude")
plt.xticks(range(0, 20, 2))
plt.ylabel("std of results")
plt.legend()